Setting a higher standard for Sikh Gurbani and Punjabi transliterations
Most of the Sikh diaspora have heard of "English Transliterations". A transliteration being something that can be converted back and forth between alphabets and languages without issue. That is, to transliterate Gurmukhi into English, and then transliterating the corresponding English to Gurmukhi with full parity and zero data loss. Even though this is possible, it can appear to the average reader like computer code. Such a pure transliteration sacrifices readability for the average consumer.
On the other hand, what many today call a "transliteration" is in fact, at best, an attempt at transcription (guide for pronunciation). Various English accents lead to differing transcriptions evident from Sikh content creators and in popular Gurbani apps today. The transcriptions most popularly used today can be very easily misread as they are interpreted by differing regions with different accents.
There is a general lack of awareness for a common standard. The goal of this article is to surmise the current thinking of transliterating gurbani and punjabi.
Overview of IAST and IPA
In hopes of creating a better transliteration for Shabad OS, I researched various romanizations of languages. There are many standards used for Sanskrit, Devanagri, and generic Indic/Brahmic scripts.
Specific schemes already exist for Panjabi/Gurmukhi, which the Sikh diaspora seems to largely ignore. For instance see "Guru" by ISO 15919 and "Panjabi" by ALA-LC (Library of Congress). Both of these models descend from the IAST (International Alphabet of Sanskrit Transliteration), which was formalized in 1894.

A reprint of the IAST Transliteration Guide, originally published in 1899
Author's note: To think that existing transliteration rules existed for over a hundred years! I really wonder how this evolved into present day transcriptions.
For those without experience in phonology (a branch of linguistics), the IPA (International Phonetic Alphabet) can be used to phonetically transcribe Gurmukhi. The IPA has been around since 1888 (around the same time as the IAST) and its scheme allows for unique characters to keep data intact compared to currently popular pronunciation guides. However, learning the symbols of the IPA would be quite difficult for the average reader. Notice the kinds of characters used in the [square brackets] below for the Sound [IPA] column.
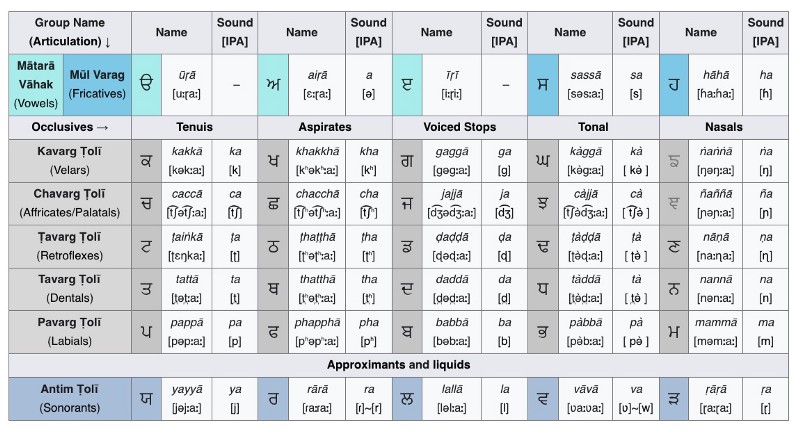
Organization of traditional Gurmukhi letters on Wikipedia
It is clear the incredible organization of the traditional Gurmukhi letter table. Excepting the first and last rows, there are sets of letters both horizontally and vertically that have something in common. Horizontally, there are rows of homorganic consonants being pronounced from the back of the mouth ("Velars") to the front using the lips ("Labials"). Vertically, the columns are dictating the manner of articulation ("Voiced Stops", "Nasals", etc.).
For example, the row with kakkā (ਕ) and gaggā (ਗ) are all pronounced with the back part of the tongue ("Velar"). But they differ in how the sound is produced. The kakkā is the simplest sound, by pushing a little air through the mouth. A gaggā requires more force and greater blocking of airflow. A ṅaṅṅā (being a "Nasal") is pronounced with air going through the nose. Continuing the example vertically, the letters in the column with kakkā (ਕ) are all produced the same way (simply with a little push of air). Similarly all the letters in the column with ṅaṅṅā are pronounced nasally.
There are 35 characters shown in the table above. As you can imagine, some of these letters overlap with the Latin alphabet. For example there are unique pronunciations for ਤ, ਥ, ਟ, ਠ, ਦ, ਧ, ਡ, and ਢ, but they are often reduced to letter combos of t, d, and h.
Transliterating Gurmukhi Consonants
Off the bat there are a few latin characters which align perfectly with the IPA:
- ਕ = k
- ਗ = g
- ਨ = n
- ਪ = p
- ਬ = b
- ਮ = m
- ਰ = r
- ਲ = l
- ਵ = v-w
In addition, these characters don't compete with other Gurmukhi letters. That's probably why all the standards listed transliterate them as such: IAST, ISO 15919, the National Library at Kolkata, Sikh Research Institute, and (with the minor substitution of a w instead of a v) the ALA-LC. There is no doubt on what these Latin letters convey in Gurmukhi and Punjabi.
From here the IPA starts to use very unique characters, which are not easy to type/learn. On the other hand, using simple characters can lead to potentially problematic aspirates and tonals such as: ਖ/kh, ਘ/gh, and ਛ/ch. For the aspirates and tonal letters, they use the "h" which is already reserved by ਹ/h. This could be an issue when working with Gurmukhi subscripts.
A real-life example would be the Punjabi word ਜਗ੍ਹਾ (place), which would be transliterated as jaghā. But to transliterate jaghā into Gurmukhi, a computer could confuse this as ਜਘਾ (not a real word). To make sure computers can transliterate Gurmukhi back and forth better, I propose the lesser used conjunct be designated with an underline (i.e. ẖ). Then ਜਗ੍ਹਾ transliterates as jagẖā. So our example of ਜਗ੍ਹਾ vs ਜਘਾ becomes easier to differentiate as jagẖā vs jaghā.
Most standards have a good sense behind overloaded characters. I've seen many transcriptions use the same latin letter "t/th" for ਤ, ਥ, ਟ, and ਠ and "d/dh" for ਦ, ਧ, ਡ, and ਢ. The published standards listed above tackle this by differentiating with a dot below latin character. For example:
- ਦਰ is dar (door) and ਡਰ is ḍar (fear)
- ਧੱਕਣ is dhakkaṇ (verb to push) and ਢੱਕਣ is ḍhakkaṇ (cap, lid, or cover)
- ਤੰਗ is ta≈g (irritate/annoy) and ਟੰਗ is ṭa≈g (hang)
- ਥੋਕ is thok (bulk/wholesale) and ਠੋਕ is ṭhok (hammer)
To learn this rule, it can be surmised as follows: the below dot represents a retroflex (Wikipedia), and should be pronounced with the tongue far back. See the below column of retroflexes and how the tongue position is similar for Punjabi sounds.
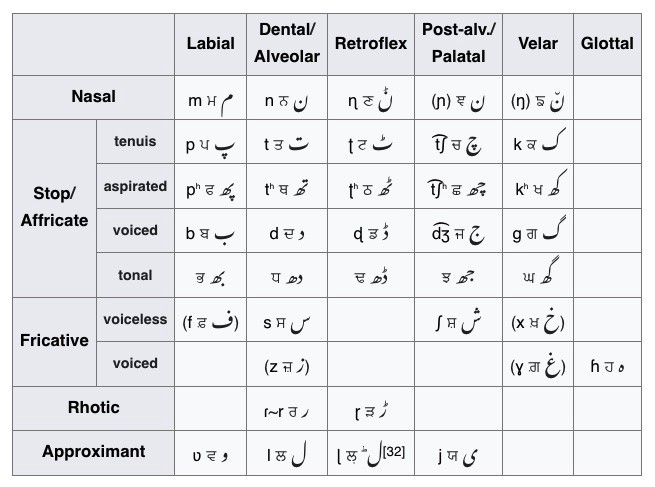
Consonant phonology of the Punjabi Language from Wikipedia. Notice the third column for "Retroflex". All of these characters are transliterated with a dot underneath.
The remaining retroflexes ਣ, ੜ, and ਲ਼ are appropriately transliterated as ṇ ṛ and ḷ in ISO 15919 and Sikh Research Institute standards, but other standards deviate from this rule.
With this we have covered a majority of the characters and their transliterations. The notable consonants remaining are nasals (ਙ, ਞ, ਣ) and modern supplementary adoptions (ਸ਼, ਖ਼, ਗ਼, ਜ਼, ਫ਼, and ਕ਼). The nasals can be differentiated with numerous diacritics. For the sake of illustrating: ń, ñ, ň, ǹ, ṅ, ṇ, ņ, ṉ, ṋ, ꞥ, ᵰ, or ᶇ.
Since the bottom dot is used for retroflex, it makes sense to transliterate ਣ into ṇ, leaving ਞ and ਙ. The IPA for ਞ states the same sound is used in Spanish (i.e. the ñ in español). Which is what the IAST, ISO 15919, ALA-LC, National Library at Kolkata, and Sikh Research Institute transliterate it as. Thus leaving ਙ, which all of these standards translit to ṅ. So these nasals in order are ਙ/ṅ (velar), ਞ/ñ (palatal), and ਣ/ṇ (retroflex).
If we wanted to follow the pattern of below dots being retroflex for other diacritics, we could signify velar characters with above dots (ṅ) and palatal consonants with above tilde (ñ).
Moving on to supplementary characters. Two are velar (ਖ਼ and ਗ਼), which according to the top dot rule become k̇h and ġ. It should also be noted that the base letters ਖ and ਗ are also velar. So the dot is not differentiating them as such, but does still follow the rule that letters with above-dot are velar. This is how the latter ġ is used in ISO 15919. However, most standards convert these to kh and gh (or stylistically underlined versions of ḵẖ and gẖ).
These overloaded combos are ambiguous for programmatic transliteration, so it doesn't make sense for us to repeat kh or gh twice. The underline format also fails to be uniform with the rule of top-dot for velar letters. And, where possible, I think plain letters should be used.
The ਖ਼ in the IPA is designated with an x, which is unused otherwise, and has the added benefit of resembling each other bisected vertically k and x.
The only remaining palatal consonant is ਸ਼. According to the rule above that would be an s with a tilde above it (very difficult to type on computers). In other languages the same sound appears as sh, sch, ch, sj, x, ş, š, ŝ, and ṣ. The ALA-LC and Sikh Research Institute use "sh". Lastly, ISO 15919, IAST, and National Library at Kolkata transliterate it as ś. I think the only two options that make sense are ś or "sh" since s with tilde doesn't work on computers. But I also think š (the APA equivalent of ʃ from the IPA) makes sense here.
Now we are left with ਜ਼, ਫ਼, and ਕ਼, which, similar to ਖ਼, have plain latin character transliterations according to the IPA. I see no reason to avoid using them as they are not latin characters overloaded with another gurmukhi character's transliteration. So as follows:
- ਜ਼ = z
- ਫ਼ = f
- ਕ਼ = q
Author's note: The further I compare standards, the clearer it becomes to me that the superior standard is the ISO 15919, which better prioritizes single latin characters matching the IPA. My only real suggestion/modification is that aspirated and tonal consonants be distinguished from conjoined subscript-h and to transliterate ਖ਼ as it does ਜ਼, ਫ਼, and ਕ਼ according to IPA (i.e. ਖ਼→x). So overall, there is just one change in the consonant table: ਖ਼ → ḵẖ → x
Transliterating Gurmukhi Vowels
The list of vowels in Gurmukhi are much smaller and aside from an optional requirement to indicate rising, neutral, or falling tones, should be mostly doable without diacritics. On the point of indicating tones, I believe it is not the job of a transliteration, but rather the role of a transcription or pronunciation. Originally, I had hoped to use sounds like é to indicate a low-to-high rising tone, e or ē to indicate a flat or steady pitch, and è as a high-to-low falling tone (similar to how it is done in Chinese transliterations; to read more see "tones" in the Wikipedia Pinyin article). However, the process of tonality in Punjabi behaves differently and can be inferred from a good transliteration process, even without explicit accent indications.
Currently, vowel transliteration is an area where most standards today are using multiple characters for one Gurmukhi letter (i.e. ਐ/ai and ਔ/au). But machines can get confused. For example, try transliterating ਦਇਆਲ and ਦੈਆਲ. Which goes with which? daiāl… or … daiāl …? It is impossible for a computer to transliterate back to Gurmukhi. Changing to a single letter would lead to a marked improvement but also create a division amongst current standards out there.
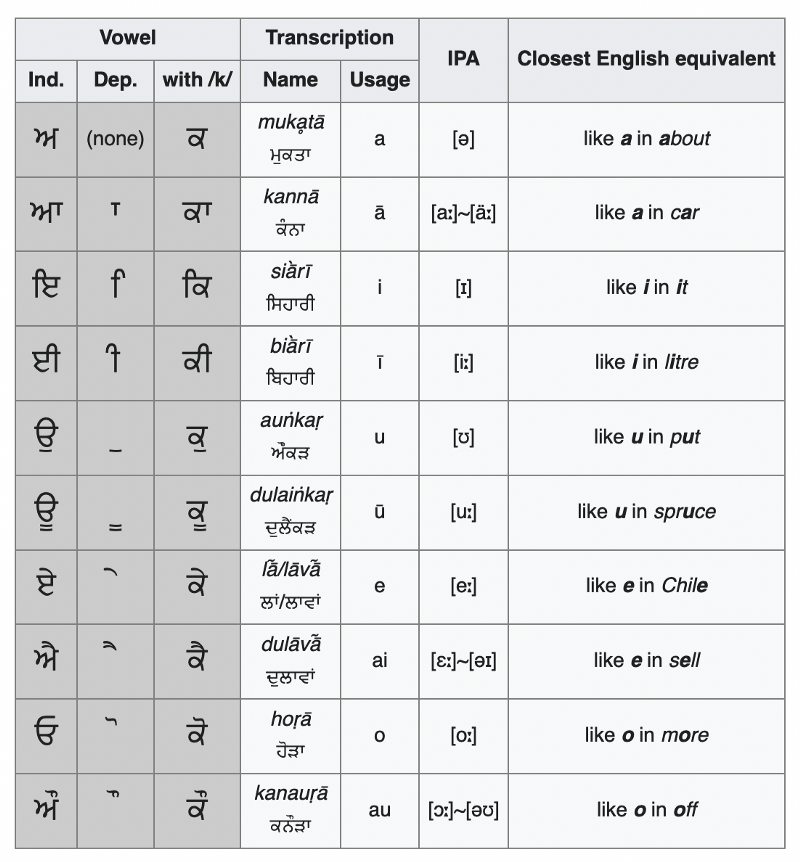
Gurmukhi vowels and their IPA approximants as seen on Wikipedia.
This is how other languages transliterate these sounds (with the Gurmukhi ISO 15919 written in parentheses):
- ਅ (a): a, i, u, and e.
- ਆ (ā): a, ā, and aa.
- ਇ (i): i or e.
- ਈ (ī): i, ī, ie, and ee.
- ਉ (u): o, oo, or u.
- ਊ (ū): oo or u, but also ù, ú, and ū.
- ਏ (ē): e, ee, ae, ay, é, ė, and ä.
- ਐ (ai): e or a, but also i, è, é, ê, ee, ae, and ä.
- ਓ (ō): o or oo, but also ó, oa, aw, and eau.
- ਔ (au): o, but also å, â, ø, and ô.
Based on this, I can see that the ISO standard for transliterating Gurmukhi does have some counterparts in other languages. It would've been best to keep with the ISO standard as much as possible, for backwards compatibility. However, I feel there must be a better way for machines to transliterate back and forth. So I propose the following changes to the ISO standard:
- ਐ (ai) → ē
- ਔ (au) → ō
And I'm not sure why extra accents were used for some characters, since they are the more popular ones. In the case of Gurmukhi, the plain e and o from the ISO standard are irrelevant. So I think this difference from the ISO standard also helps:
- ਏ (ē) → e
- ਓ (ō) → o
Going back to the example of ਦਇਆਲ and ਦੈਆਲ. Now it's clear that daiāl is different from dēāl. But the visual change and mix-up of standards can be confusing for the average reader. Counter that with making it possible for computers to transliterate back to Gurmukhi safely. Perhaps it is time we consider whether to keep confusing latin vowels such as au being ਔ or ਅਉ.
Transliterating accessory signs and other symbols
Suprasegmentals involving more than one consonant or vowel are the last piece in filling out the transcription model. These features include nasalization, tone, stress, and gemination. We will only be tackling nasalization and gemination.
Nasalization
Nasalization in Punjabi can spread forward or backward, even across syllables (e.g. ਭਾਵੇਂ could be transliterated as bhāve~, but is often pronounced with more nasalization as bhā~ve~), so we will focus only on transliteration in this article. Both symbols ṭippī ( ੰ ) and bindī ( ਂ ) represent the same concept but are typically used on different characters. If it is on either a short vowel or a consonant with long vowel ū then use a ṭippī, otherwise use a bindī. The sound both characters make is a nasalization at the same place of articulation as the following consonant. So for example:
- ਸਿੰਗ (velar nasalization ਙ) → siṅg
- ਗੂੰਜ (palatal nasalization ਞ) → gūñj
- ਗੰਢ (retroflex nasalization ਣ) → gaṇḍh
- ਅੰਤ / ਇੰਨਾ (dental nasalization ਨ) → ant / innā
- ਅੰਬ / ਅੰਮ੍ਰਿਤ (labial nasalization ਮ) amb / ammrit
There are a few issues here. For example, a nonsensical comparison of ਅੰਤ and ਅਨ੍ਤ both become "ant". Again, a unique character that can represent ṭippī and bindī would cause less issue for computer transliteration. The ISO standard uses ṁ and ṃ respectively (aṁt and iṁnā). I personally find the usage of the m confusing, and would rather use tildes ⸞ and ⸛ which represent nasalization in the IPA. So a⸛t and i⸛nā. When it comes to pronunciation, it is best to keep with the existing mappings.
Gemination
Gemination is used either to lengthen or stress a consonant. Most schemes simply duplicate the letter being lengthened/stressed, and for transcription I would agree with that method. For a transliteration model, however, I believe a breve symbol ˘ is unique for programmatic conversion.
- ਦੁੱਧ → duddh / du˘dh
- ਇੱਜ਼ਤ → izzat / i˘zat
- ਹੱਥ → hatth / ha˘th
- ਦਿੱਲੀ → dillī / di˘lī
- ਬੱਚਾ → baccā / ba˘cā
Subjoined Consonant Clusters
Lastly, consonant clusters can occur as subscript characters or because of ellisives as shown in the "Gemination/Stress" paragraph above. Because transliteration requires clarity, consonant clusters must be distinct from each other. More research is required to see what combinations exist. For transliteration it is always possible to find unique characters. As an example of transcription, please see below:
- ਪ੍ਰੇਮ → prem
- ਤ੍ਰੇਲ → trel
- ਸ੍ਵਰਗ → svarag
- ਚੜ੍ਹ → caṛẖ
Future work
After finishing up a new transliteration model, the next step becomes transcription or pronunciation. For this, we still require a set standard that ignores accents. It should be that the letters mean something to the reader, and it's probably best to try and keep in line with the transliteration standards outlined above.
A couple ways of converting from transliteration to transcription is to loosen the requirement for unique letters and doing studies into schwa deletion (or mukta elision). Afterwards it would also be helpful to look into stressed syllables. Please refer to page 50 of "A Descriptive Grammar of Hindko, Panjabi, and Saraiki" on potential transliteration rules which can look more natural.
Author's note: As far as I can tell, stress is on the penultimate, unless the ultimate is heavier. And it's on the antepenultimate (third from last) if it's heavier than both the penultimate and ultimate syllables. If all three syllables are the same, it again defaults to penultimate. This seems to work for four letter words, but many three letter words don't follow this rule as their schwa deletion comes into the equation.
- Initial Word → Transliteration (Pingal) → Stress/Syllable → Common Spelling
- ਸਿਮਰਨ → simarana (1111) → sim'ran → simran
- ਸਲਵਾਰ → salawāra (1121) → sal'wār → salwar
- ਚਮਕੀਲਾ → camakīlā (1122) → cam'kī.lā → camkīlā
- ਕਰਦਾ → karadā (112) → kar'dā → kardā
- ਖ਼ਾਲਸਾ → xālasā (212) → xāl'sā → xālsā
The above may not prove safe for transliteration, but serves as a step towards further transcription (pronunciation) engines. This also only just barely scratches the surface and a lot of research has been done into syllabification of the various languages used in the Shabad OS Database, which can help as well. Please refer to the work being done in the gurmukhiutils project for more info.
Typing the transliteration in day-to-day practice
On macOS and iOS if you press-and-hold a letter, other letter options appear. The following letters are available:
- ñ for ਞ
- ś for ਸ਼
- ā for ਆ
- ī for ਈ
- ū for ਊ
- ē for ਐ
- ō for ਔ
Some letters are troublesome such as pēr-haha, super-dot and sub-dot (e.g. ṅ and ṇ), and nasalization. If you add the ABC Extended keyboard layout on macOS, you can type extra symbols by preceding the letter with a hotkey. For example <option-x, r> will result in ṛ (see below for the relevant codes):
<option-n>for ˜ (ñ)<option-x>for . (ṭ, ṛ)<option-w>for ˙ (ṅ, ġ)<option-h>for ˍ (ẖ)<option-b>for ˘(breve / addhak)
Note: As of writing, the hotkeys on mac are not available for iOS.
A custom keyboard could be used to type english, transliteration characters, and gurmukhi, similar to what an IME for Pinyin does. One such keyboard exists, LipikaIME, which provides support for all Indic Languages using the ISO standard. So if you're interested, that might be a good place to start.
Bringing it all together
More efforts need to be done in the Sikh sphere to start working towards a common standard for transliteration and transcription. Basically we need to decide as a group what latin letters express what. The above article goes over various published standards with logic for a sensible model. In short follow the ISO 15919 with either a flexible or hard change on the following:
- Distinguishing aspirates (e.g. kh or gh) and subjoined-h (e.g. kẖ or gẖ)
- Reducing confusion of vowel letter clusters with single latin letter expressions (e.g. au to ō and ai to ē)
- Option to change ਖ਼ to x per IPA -- the same as it is for ਜ਼ (z), ਫ਼ (f), and ਕ਼ (q)
It is also important to note the difference between transliteration and transcription. When it comes to day to day speech, Punjabi is very different from the expressed Gurmukhi. If one were to read and pronounce punjabi words the way they do with gurbani, they would sound odd and unnatural to native speakers. More research is required in this field, but there are many scholarly articles published on the subject from various authors. This area gets into differing pronunciation rules for Gurbani and Punjabi as well, which perhaps cannot be fully standardized.
With the Shabad OS python library, titled gurmukhiutils, it is possible to go from old ascii representations of gurbani to unicode with zero data loss. The next goal is to be able to convert gurbani to a latin transliteration which can be translated back to the original unicode. And from there to then work on a transcription model for natural gurbani pronunciations (assuming a basic knowledge of transliteration/transcription models). If you're interested in this sphere of work, keep an eye on the gurmukhi utils project!